快取機制完全攻略:基本概念、系統效能影響與實作指南
更新日期:2025 年 5 月 19 日
在數位世界中,速度就是一切。無論是網頁載入時間、資料庫查詢還是API回應,使用者都期待瞬間得到回應。快取機制正是實現這一目標的關鍵技術。本文將深入探討快取的本質、其對系統效能的重大影響,以及如何通過簡單的程式碼實作你自己的快取系統,幫助你的應用程式脫穎而出。
什麼是快取機制?
快取(Cache)是一種暫存資料的技術,其主要目的是儲存曾經獲取或計算過的資料,以便將來再次需要相同資料時能夠快速取得,而不必重新計算或從原始資料來源重新獲取。
簡單來說,快取就像是我們的「記憶筆記本」,將可能重複使用的資訊記下來,下次需要時直接查閱筆記本,而不是再次查詢原始資料。這大大節省了時間和計算資源。
快取的工作原理
快取系統的基本工作流程如下:
- 查詢快取:當系統需要某項資料時,首先檢查快取中是否已存在該資料。
- 快取命中(Cache Hit):如果快取中存在所需資料,直接從快取中獲取,這被稱為「快取命中」。
- 快取未命中(Cache Miss):如果快取中不存在所需資料,系統需要從原始資料來源(如資料庫、API 等)獲取資料。
- 更新快取:獲取到新資料後,將其存入快取中,以便未來使用。
- 快取過期:為了確保資料的新鮮度,快取中的資料通常會設置一個過期時間,超過後需要重新從原始來源獲取。
常見的快取類型
依據存儲位置和用途,快取可以分為多種類型:
- CPU快取:位於處理器內部,用於存儲經常使用的指令和資料,分為 L1、L2、L3 等多級快取。
- 記憶體快取:應用程序在RAM中建立的快取,如 Redis、Memcached 等。
- 硬碟快取:將資料暫存在硬碟上的特定區域,如瀏覽器的磁碟快取。
- CDN快取:內容分發網路中,將靜態資源分散存儲在全球各地的節點。
- 資料庫快取:資料庫系統中用於加速查詢的快取機制,如查詢結果快取、索引快取等。
- 應用程式快取:在應用程式代碼層面實現的快取,如將API響應結果暫存。
快取機制的演進
快取技術的發展可以追溯到計算機科學的早期,當時CPU和主記憶體之間的速度差距促使研究人員開發了快取層。從簡單的記憶體區塊到如今複雜的多層級、分散式快取系統,這項技術不斷進化。
快取技術的發展里程碑:
- 1960年代:IBM System/360 首次引入CPU快取的概念。
- 1990年代:隨著網際網路的發展,Web代理伺服器開始用於內容快取。
- 2000年代早期:分散式記憶體快取系統如Memcached開始流行。
- 2009年:Redis發布,提供更豐富的資料結構和持久化選項。
- 2010年代:CDN技術廣泛應用,邊緣計算與快取相結合。
- 現今:多層級快取架構、智能預取策略以及基於機器學習的快取優化方案不斷涌現。
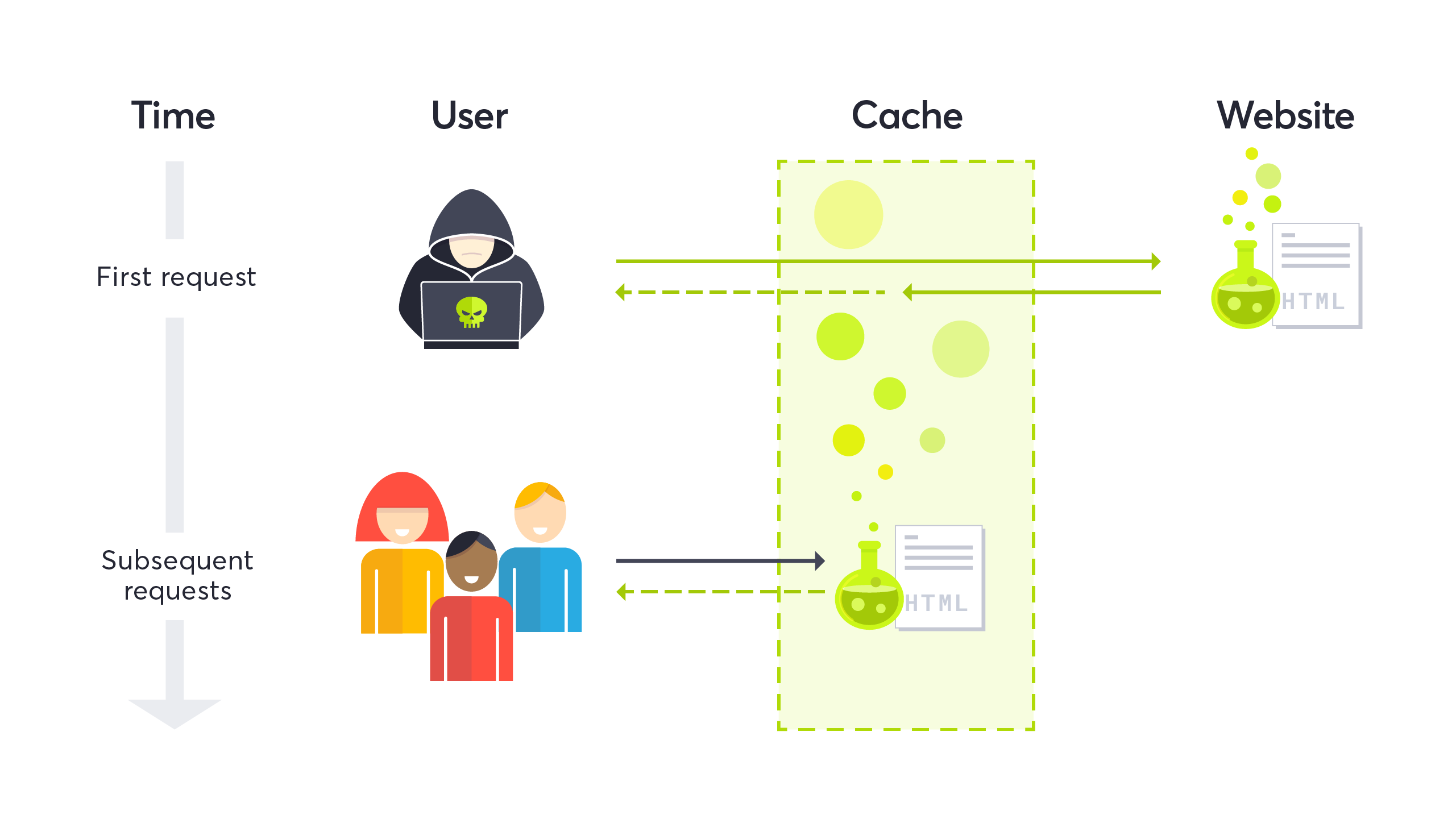
快取機制對系統效能的影響
快取技術對現代系統效能產生了深遠的影響,良好的快取策略可以帶來顯著的效能提升,但設計不當的快取也可能引發問題。了解這些影響有助於我們更有效地應用快取技術。
正面影響
- 減少回應時間:從快取獲取資料比從原始來源(如資料庫或遠端API)快數十倍甚至數百倍。
- 降低系統負載:減少了對後端資源(如資料庫、API服務器)的請求次數,降低其負載。
- 提高並發處理能力:由於減少了I/O操作和計算量,系統能夠處理更多的並發請求。
- 節省頻寬成本:CDN快取減少了從源站到用戶的資料傳輸,節省了頻寬成本。
- 改善用戶體驗:較短的載入時間和回應時間直接提升了用戶體驗和滿意度。
潛在的負面影響
- 資料一致性問題:快取中的資料可能與原始資料源不同步,導致資料不一致。
- 快取過期設置困難:設置過短會降低快取效率,設置過長會增加資料不一致的風險。
- 快取穿透:大量查詢不存在的資料繞過快取直接訪問資料庫,導致系統崩潰。
- 快取雪崩:大量快取同時過期,造成後端系統短時間內收到大量請求。
- 記憶體開銷:快取佔用系統記憶體資源,需要合理規劃和管理。
快取效能案例分析:電商平台
以一個電商平台為例:在沒有快取的情況下,每次用戶瀏覽商品頁面都需要從資料庫查詢商品資訊、價格、評論等資料,並進行複雜的排序和過濾操作。假設每個頁面需要 500ms 的處理時間,當有 1,000 個並發用戶時,系統可能難以承受負載。
實施多層快取策略後:
- 商品基本資訊被快取到 Redis 中,查詢時間從 200ms 降至 5ms
- 熱門商品頁面被完整快取,回應時間從 500ms 降至 50ms
- 靜態資源通過 CDN 分發,載入時間減少 60%
- 資料庫查詢率降低 80%,數據庫服務器 CPU 使用率從 90% 降至 30%
最終結果:系統能夠輕鬆處理 5,000 個並發用戶,頁面載入時間減少 70%,轉換率提升 15%。實際測量的命中率達到 85%,意味著大多數請求都能直接從快取獲取資料,極大地提升了效能。
常見的快取策略與演算法
設計有效的快取系統不僅需要了解基本概念,還需要選擇適合的快取策略和替換演算法。不同的應用場景可能需要不同的策略組合。
快取策略
- Cache-Aside(旁路快取):應用程式先查快取,未命中時從資料庫獲取並寫入快取。最常用的策略,實作簡單。
- Read-Through:快取負責從資料源加載資料,對應用透明。應用只與快取交互,由快取處理未命中情況。
- Write-Through:數據同時寫入快取和資料庫,保證一致性但寫入延遲較高。
- Write-Behind:數據先寫入快取,再異步寫入資料庫,提高寫入效能但增加數據丟失風險。
- Write-Around:數據直接寫入資料庫而不更新快取,適合寫入後不立即讀取的場景。
快取替換演算法
當快取空間有限時,系統需要決定哪些資料應該被保留,哪些應該被淘汰:
- LRU(Least Recently Used):淘汰最長時間未被訪問的資料,最常用的演算法之一。
- LFU(Least Frequently Used):淘汰訪問次數最少的資料,適合訪問頻率相對穩定的場景。
- FIFO(First In First Out):淘汰最早進入快取的資料,實作簡單但不考慮資料熱度。
- ARC(Adaptive Replacement Cache):結合頻率和時間因素的自適應演算法,在多種場景下表現更佳。
- TLRU(Time-aware LRU):考慮資料過期時間的LRU變種,適合有明確過期時間的資料。
流行的快取系統
現代開發中常用的快取系統包括:
- Redis:記憶體資料結構存儲,支持豐富的資料類型和持久化,廣泛用於分散式快取。
- Memcached:高效的分散式記憶體快取系統,專注於簡化和高效能。
- Varnish:HTTP加速器和反向代理,適合Web內容快取。
- Ehcache:Java生態系統中流行的本地快取庫。
- CDN服務:如Cloudflare、Akamai等,提供全球內容分發和快取。
實作一個簡單的快取系統
理解了快取的原理和策略後,讓我們通過實際程式碼來實作一個基本的快取系統。我們將使用 JavaScript 實現常見的快取替換策略:FIFO(First In First Out)快取。
FIFO(先進先出)快取策略
FIFO 快取策略是一種簡單的記憶體替換演算法。當快取已滿時,會移除最早加入快取的資料,給新資料騰出空間。這種方式適用於對時間敏感但不需要複雜邏輯的場景。
為什麼使用 Map 和 Array?
在這個實作中,我們選擇使用 JavaScript 的 Map 和 Array:
- Map:可以高效地儲存和讀取鍵值資料(key-value),並且保有插入順序。
- Array:用來記錄 key 的插入順序,方便我們根據 FIFO 策略移除最早加入的 key。
資料存在哪裡?(瀏覽器記憶體 RAM)
當你在瀏覽器中執行 JavaScript 程式碼時,所有變數與資料結構(包含快取)都會存在於瀏覽器的「記憶體(RAM)」中。這些資料屬於「暫時性資料」,當你重新整理頁面或關閉分頁時,這些資料就會被清除。
所以這種快取策略適合應用在短期快取場景,例如:API 回應的快取、使用者暫時操作的資料記錄、瀏覽器前端效能優化等。
FIFO 快取 JavaScript 實作
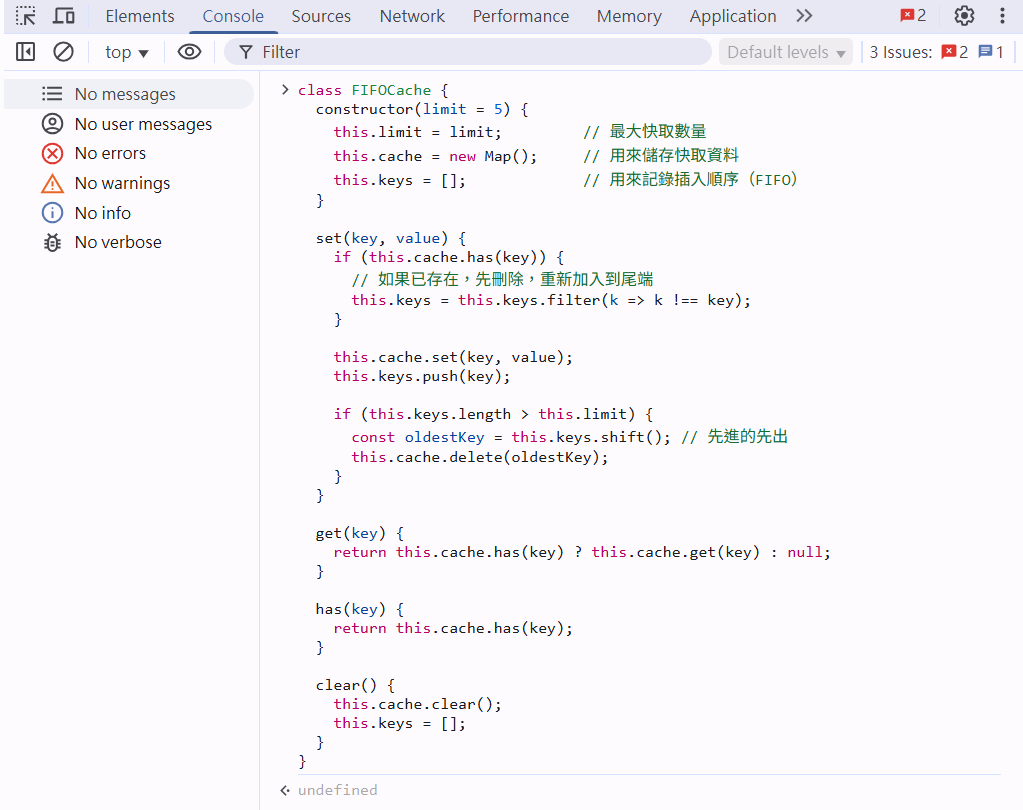
class FIFOCache {
constructor(limit = 5) {
this.limit = limit; // 最大快取數量
this.cache = new Map(); // 用來儲存快取資料
this.keys = []; // 用來記錄插入順序(FIFO)
}
set(key, value) {
if (this.cache.has(key)) {
// 如果已存在,先刪除,重新加入到尾端
this.keys = this.keys.filter(k => k !== key);
}
this.cache.set(key, value);
this.keys.push(key);
if (this.keys.length > this.limit) {
const oldestKey = this.keys.shift(); // 先進的先出
this.cache.delete(oldestKey);
}
}
get(key) {
return this.cache.has(key) ? this.cache.get(key) : null;
}
has(key) {
return this.cache.has(key);
}
clear() {
this.cache.clear();
this.keys = [];
}
}
// 使用範例
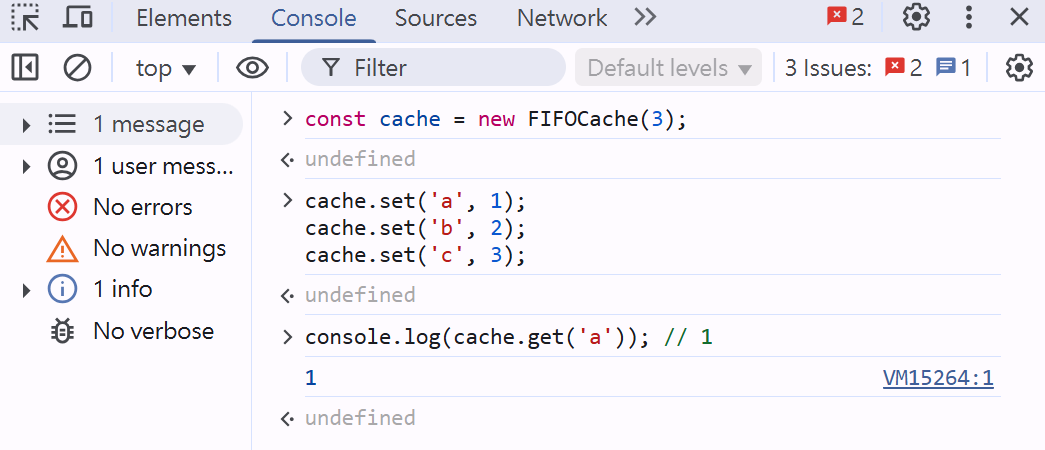
const cache = new FIFOCache(3);
cache.set('a', 1);
cache.set('b', 2);
cache.set('c', 3);
console.log(cache.get('a')); // 1
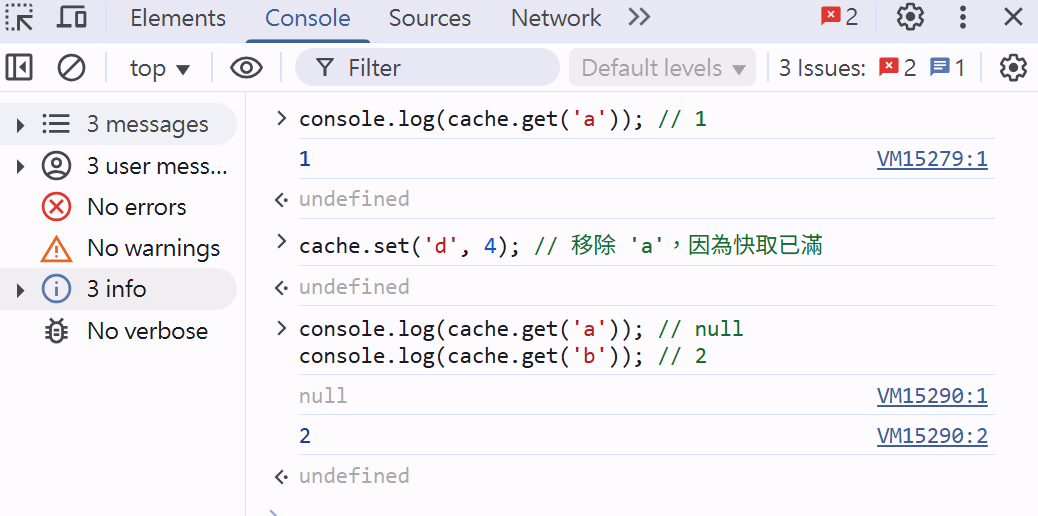
cache.set('d', 4); // 移除 'a',因為快取已滿
console.log(cache.get('a')); // null
console.log(cache.get('b')); // 2
如何測試 FIFO 快取功能?
你可以使用瀏覽器的開發者工具(DevTools)直接測試這段快取邏輯:
- 開啟瀏覽器(建議使用 Chrome)。
- 按右鍵 → 點選「檢查」 → 選擇「Console」分頁。
- 將上述程式碼貼上,按下 Enter 執行。
- 觀察
console.log()印出的結果,確認快取是否按照 FIFO 順序淘汰舊資料。
進階觀察
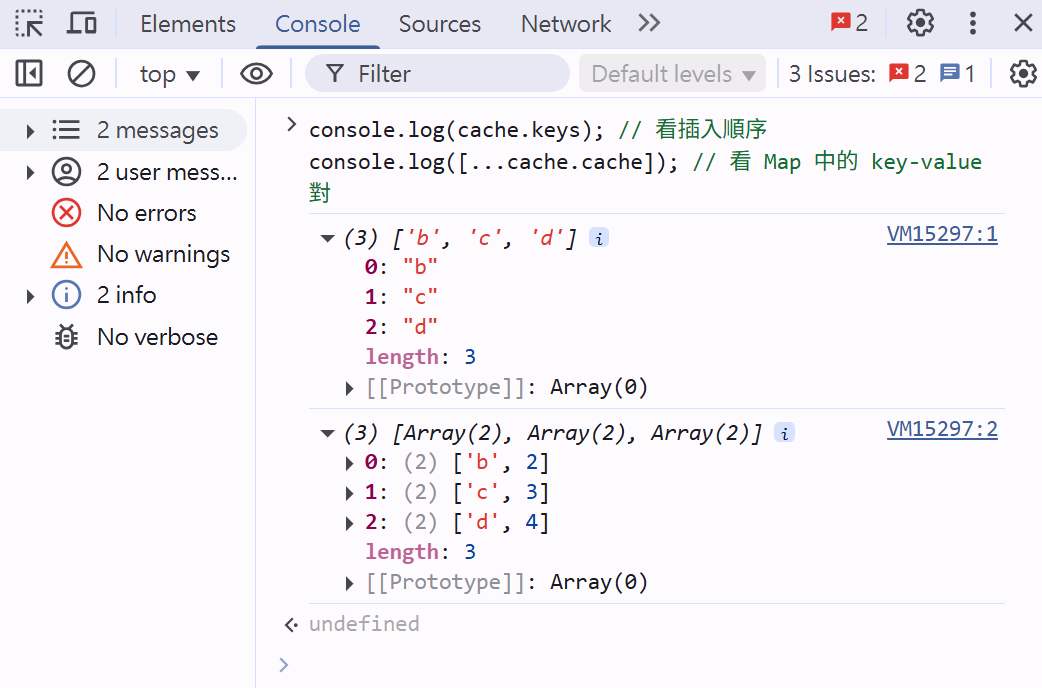
如果你想更直觀地觀察快取狀態,可以輸出整個快取的 key 列表或內容:
console.log(cache.keys); // 看插入順序
console.log([...cache.cache]); // 看 Map 中的 key-value 對Cache流程與變化
- 開啟瀏覽器(建議使用 Chrome)。,建立物件
- 寫入快取值
- 先來後到,查看快取值,與移除快取流程
- 進階查看目前快取值的內容與變化
結語
在這個實作中,我們定義了一個 `FIFOCache` 類別,具有 `set`、`get`、`has` 和 `clear` 方法。在 `set` 方法中,如果快取已滿,我們就會刪除最先加入的 key,這就是 FIFO 策略的核心。
這種快取機制適合用於一些簡單且對效能要求不極端的場景,例如瀏覽器端的暫存、API 回應暫存等。如果你需要更進階的策略(如 LRU、LFU 等),可以再進一步擴充資料結構與演算法邏輯。